En esta última parte del grupo de artículos centrados en clases que pueden funcionar como colecciones alternativas a matrices convencionales vamos a examinar y comparar el rendimiento de NestedDictionary<T> con el de una matriz JaggedArray representada por T[][].
Para comparar el rendimiento de las dos estructuras se han realizado una serie de operaciones en distintos escenarios variando la densidad de objetos almacenados, el tamaño de la matriz y el tamaño de la submatriz de búsqueda en área.
Resultados comparativos entre NestedDictionary<T> y T[][]
El primer test consiste en aplicar la operación GetAllToList sobre ambas colecciones. Dicha operación busca y guarda en una lista todos los objetos no nulos contenidos en la colección. La ventaja de NestedDictionary es que sólo contiene entradas no nulas; mientras que T[][] tiene que reservar espacios de memoria que estarán inicializados a null hasta que se almacene un objeto en ellos.
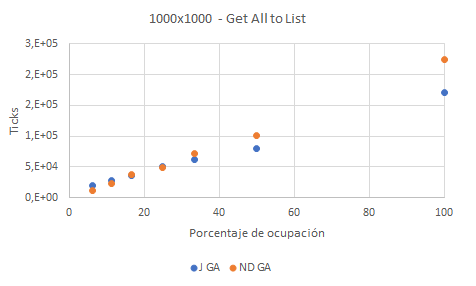
La gráfica muestra el resultado del test sobre las dos colecciones. J GA señala JaggedArray Get All, mientras que ND GA señala NestedDictionary Get All. El número de Ticks —10.000 ticks equivalen a un milisegundo—, en el eje y, indica el tiempo necesario para realizar la operación; por tanto, menor número de ticks implica mayor rendimiento.
La tendencia observada es que T[][], es decir, JaggedArray es más rápida para porcentajes de ocupación altos, es decir, para colecciones densas donde prácticamente todos los huecos están ocupados. No obstante, para porcentajes de ocupación bajos —por debajo del 25%— o Colecciones Dispersas, NestedDictionary tiene un mayor rendimiento dado que T[][] tiene que verificar todas las celdas de una matriz 1000×1000 y sólo añadir a la lista los objetos no nulos, mientras que NestedDictionary sólo contiene registros no nulos, evitando tener que realizar verificaciones adicionales.
El siguiente conjunto de pruebas tiene por objetivo realizar distintas operaciones de búsqueda en área con distintas condiciones iniciales y variando distintos parámetros. El primero de ellos trata de encontrar todos los objetos que haya en una submatriz de 50×50 —trazada desde la coordenada 200 a la 249 tanto para x como para y—; dicha submatriz está contenida dentro de la colección completa que ocuparía un tamaño de 500×500. Los resultados se muestran para un tamaño de búsqueda constante modificando los valores de la densidad de ocupación.
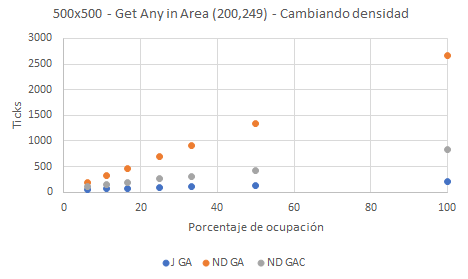
Los resultados en la gráfica muestran tres familias de datos. J GA señala JaggedArray Get in Area, mientras que para NestedDictionary tenemos dos métodos de búsqueda: ND GA señala NestedDictionary Get in Area, ND GAC señala NestedDictionary Get in Area Contains. La diferencia entre estos dos últimos métodos está detallada en el primero de este grupo de artículos y radica en el uso del método Dictionary.ContainsKey().
En un primer vistazo es evidente que T[][] es más rápido en todas las situaciones dado que, como se indicó, esta estructura es muy compacta y almacena de forma ordenada los objetos en memoria haciendo que las búsquedas en área sean siempre más rápidas. Por otro lado, para este tamaño de búsqueda en área —submatriz de 50×50—, parece que el método Contains, representado en gris, es siempre más rápido que el que no utiliza Contains, en naranja. En posteriores pruebas veremos que esto no siempre es así.
Por lo general, podemos apreciar que los tiempos de búsqueda se aproximan conforme el porcentaje de ocupación disminuye y la colección se va haciendo más dispersa hasta estar prácticamente vacía. Para el porcentaje de ocupación del 100% J GA tiene un valor de 215 Ticks, ND GA obtiene 2662 Ticks (12,36 veces más lento) y ND GAC obtiene 840 Ticks (3,90 veces más lento). Por otro lado, para valores de alta dispersión con una ocupación del 6,3%, J GA tiene un valor de 55 Ticks, ND GA obtiene 193 Ticks (3,54 veces más lento) y ND GAC obtiene 108 Ticks (1,97 veces más lento).
Finalmente volvemos a hacer una comparación de búsquedas en área en dos escenarios complementarios al anterior: ahora mantienen la densidad de ocupación constante y modifican el tamaño del área de búsqueda. El primer test se hace en una matriz de 500×500. De los 250.000 objetos que cabrían sólo están ocupadas 62.500 posiciones. En este caso, en el eje x se muestra el tamaño del área de búsqueda respecto del área total de la matriz; por ejemplo, el valor de 70 implicaría que la superficie de búsqueda cubre el 70% de la colección bidimensional.
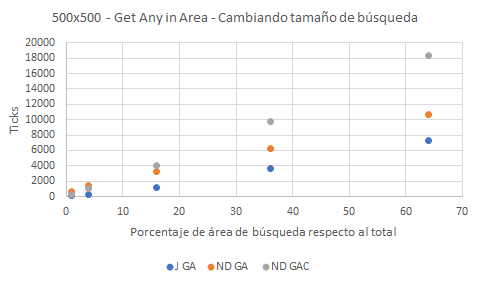
Los resultados representados en la gráfica superior nos permiten comprobar la diferencia entre ND GA y ND GAC. En situaciones donde el área de búsqueda es grande respecto al total —entre el 60% y el 70% mostrado en la gráfica— el método ND GAC, que usa Contains, requiere más Ticks, y es más lento que ND GA, en naranja. Sin embargo, cuando el tamaño del área de búsqueda disminuye —valores por debajo del 20% en la gráfica—, vemos que ambos métodos se aproximan y que finalmente hay una inversión en favor de ND GAC haciéndose este último más rápido.
Para concluir, volvemos a realizar un test similar a este último donde únicamente se ha modificado la población inicial de objetos, que disminuye de 62.500 a 27.889.
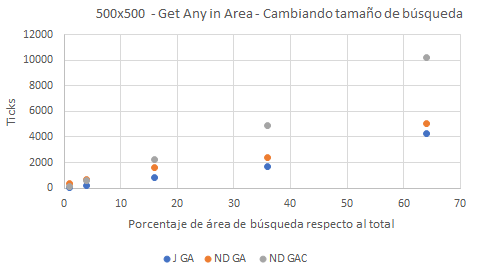
En esta última prueba vemos que al tener una colección más dispersa, los valores del método de búsqueda para NestedDictionary, en naranja, están mucho más próximos a los de la matriz JaggedArray, en azul. Este hecho no debería sorprendernos a la vista de lo mencionado hasta ahora: a menor densidad y mayor dispersión mejores resultados tendremos usando diccionarios anidados y más nos aproximaremos a los resultados de una colección tipo T[][]. Una vez más vemos que para áreas grandes de búsqueda —entre el 60% y el 70% mostrado en la gráfica— el método que usa Contains, ND GAC en gris, es más lento que su homólogo que no lo usa, en naranja; sin embargo esta tendencia cambia en valores bajos y ND GAC acaba siendo más rápido.
Conclusiones
A lo largo de esta serie de artículos se han expuesto dos posibles implementaciones de colecciones alternativas a T[][] especialmente útiles en situaciones de alta dispersión. La principal ventaja de NestedDictionary y CoordinatedDictionary2D es que la estructura de diccionarios no necesita tener un tamaño fijado a priori, permitiendo almacenar objetos mediante índices arbitrariamente separados entre sí, así como la posibilidad de usar índices que no sean números enteros —por ejemplo strings—. Por contra, la estructura T[][], aún siendo más rápida en búsquedas en área, requiere saber a priori el tamaño de la matriz, haciendo que los índices no puedan salirse del intervalo prefijado y generando superficies que, en situaciones de baja ocupación, dan lugar a matrices de gran tamaño prácticamente vacías donde sólo los lugares ocupados tienen interés.
Los resultados descritos muestran una tendencia que respaldan lo aquí expuesto: para densidades bajas, la búsqueda y recolección de datos —primera gráfica del artículo— es más rápida en NestedDictionary que en T[][]. Para búsquedas en área T[][] es siempre más rápida; no obstante, los valores para los tiempos de ejecución siempre se acaban aproximando con NestedDictionary para colecciones dispersas.
En posteriores artículos, relacionados con la generación dinámica de textos en tiempo real mediante algoritmos basados en cadenas de Markov, mostraremos ejemplos concretos de implementaciones donde el uso de mapas anidados y estructuras equivalentes a NestedDictionary pueden dar lugar a resultados notables tanto en rendimiento como en la calidad de las cadenas de texto obtenidas.
